-
产品优势
-
产品功能
-
应用场景
-
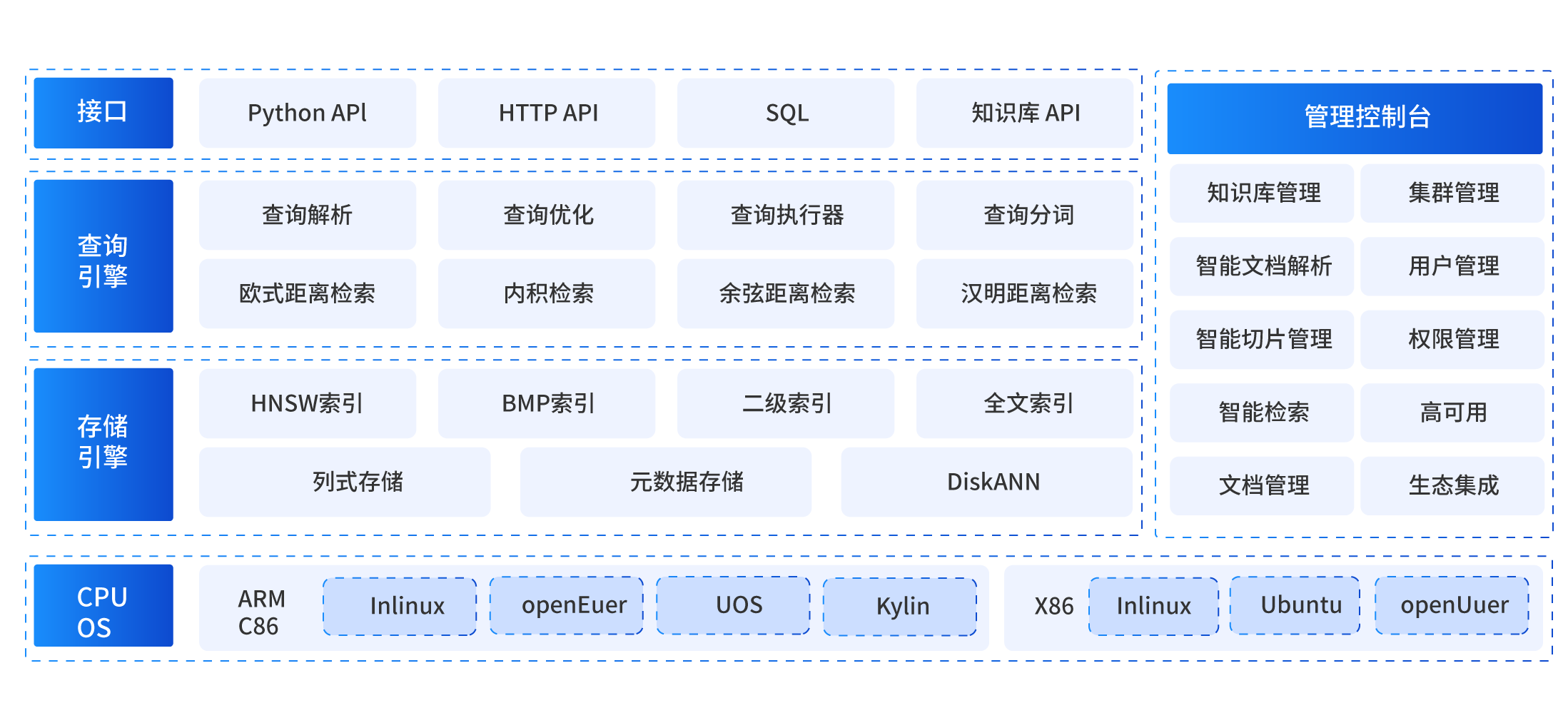
产品架构
-
解决方案
-
产品优势

 多模数据存储查询
多模数据存储查询支持向量、张量、结构化、全文数据存储;支持指定单列、多列向量查询;支持多种数据类型混合查询;支持多表关联查询
 多路召回、融合排序
多路召回、融合排序支持稀疏向量数据、稠密向量数据、全文数据三路召回查询,支持算子级别的倒数排序融合(RRF)算法和自定义策略进行融合排序,支持各类基于模型的重排序方法
 高性能、高可靠
高性能、高可靠通过自适应量化和内存优化的HNSW向量索引技术,单节点即可支持万级 QPS 及亚毫秒级查询延迟, 支持分布式架构及高可用模式
 一站式解决方案
一站式解决方案自带RAG,可构建面向大模型和RAG/Agent系统的数据底座,为大模型知识库原始数据、索引数据的存储、检索提供一站式解决方案
产品功能

- 支持多模态向量存储、检索
支持稀疏向量数据、稠密向量数据、张量三种向量存储及精准检索和近似检索
- 支持全文检索
支持建立全文索引及根据字段进行检索
- 支持结构化数据存储查询
支持30多种类型的结构化数据的存储、条件查询
- 支持多路召回及融合排序
支持稀疏向量、稠密向量、张量及全文检索等多种召回方式;支持全文精确+向量语义召回加权得分、倒数排名融合 (RRF)策略进行排序
- 支持一站式文档检索
通过多种格式文档的上传、自动智能切片、切片信息补充、知识图谱构建、向量化和自动索引构建等措施进行知识库构建;通过融合检索、知识图谱检索、上下文检索等多种措施进行增强的内容检索、操作进行知识库的增强检索
- 多种接入方式
提供了python、http和sql三种客户端接入模式,客户可自主选择接入方式,实现多元化数据管理方式
应用场景
-
检索增强生成(RAG)
-
智能问答系统
-
大模型上下文记忆
-

基于大模型的推理能力,针对私有云场景的私域知识构建知识库。
-

交互式智能聊天机器人,自动回答用户问题;保持大语言模型与用户的会话信息,检索相关性高的上下文,生成提示词配合大模型问答,降低幻觉情况发生。
-

保持大语言模型与用户的会话信息,检索相关性高的上下文,生成提示词配合大模型问答,降低幻觉情况发生。
产品架构